

Do you want to attend FREE Bootcamp of IT courses?
Do you want to learn & get a job in Data Science?
06 May 2023
Gradient Boosting: The Ultimate Tool for Advanced Machine Learning

Ekeeda Moderator
Works at Ekeeda

So, what is Gradient Boosting, and how can it help you become a better machine learning practitioner? It's an algorithm that uses decision trees and ensemble learning to make accurate predictions for both classification and regression problems.
In this guide, we'll explore these questions and more as we dive deep into the world of Gradient Boosting in Machine Learning. Get ready to unlock your potential and become a master of this advanced technique!
What Is Gradient Boosting
Gradient Boosting is a machine learning technique that can help computers learn to make better predictions. Imagine you have a big dataset of information and you want to predict something, like whether someone will buy a product or not.
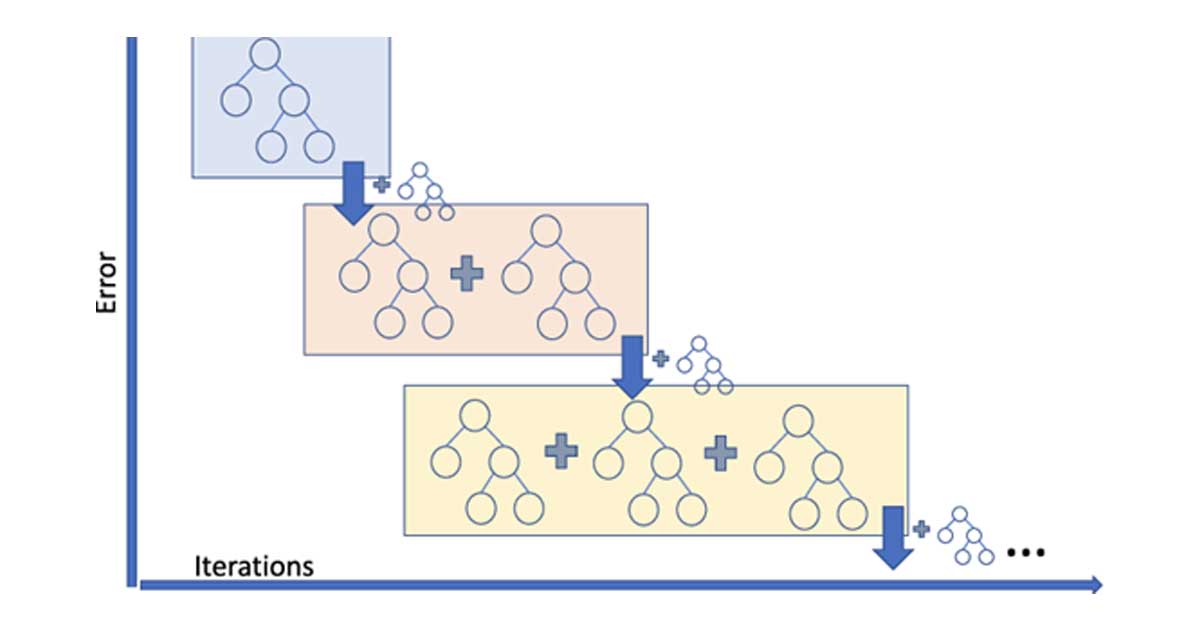
Instead of using just one model to make the prediction, Gradient Boosting combines many "weak" models, like decision trees, to create a "strong" ensemble model that can make more accurate predictions.
Each model is trained to find patterns in the data, and then the errors of the previous models are used to improve the next model's predictions. This process repeats until the ensemble model is accurate enough to make the prediction with high confidence.
Gradient Boosting is a popular algorithm because it can handle large datasets and complex features, making it useful for many real-world applications like predicting stock prices, diagnosing diseases, and more.
Gradient Boosting is an iterative machine learning algorithm that is used to improve the accuracy of a model over time.

In Gradient Boosting, decision trees are a machine-learning technique used as the building blocks for creating a model. Decision trees are like flowcharts that help to make decisions based on a series of conditions.
In the case of Gradient Boosting, a decision tree is created for each iteration of the model-building process. The first decision tree is built on the entire dataset, and subsequent decision trees are built on the errors or residuals of the previous tree.
Each decision tree is created by choosing the best-split points for the features in the data. The split points are chosen based on the reduction in the error or loss function. The goal is to split the data into groups that are as homogeneous as possible in terms of the target variable.
Once all the decision trees are built, they are combined to make the final model. Each decision tree contributes a small improvement to the overall model.
In summary, decision trees are the fundamental building blocks of Gradient Boosting. They are used to create a sequence of models that improve on each other, ultimately resulting in a highly accurate model for classification or regression problems.
Ensemble learning is a machine learning technique that combines multiple models to improve the accuracy of predictions. In Gradient Boosting, we use ensemble learning to combine the outputs of multiple decision trees to create a more powerful and accurate model.
This process of combining decision trees is called boosting. Boosting iteratively adds decision trees to the model, with each subsequent tree learning from the errors of the previous tree. The final model is a combination of all the trees, with each tree contributing to the overall prediction.
Ensemble learning also helps to reduce overfitting, which is when a model is too complex and performs well on the training data but poorly on new data. By combining multiple models, the overall model is more robust and can generalize better to new data.
Gradient Boosting For Classification And Regression
Gradient Boosting is a powerful technique that can be used for both classification and regression problems in machine learning. In classification problems, the goal is to predict which category a data point belongs to.
For example, we might want to predict whether an email is spam or not spam. In regression problems, the goal is to predict a numerical value, such as the price of a house or the number of hours of sunshine in a day.
Gradient Boosting can be used to build a model that can accurately predict the output value or category of a new data point. It works by combining multiple decision trees, where each tree is trained to predict the error of the previous tree. This iterative process continues until the model reaches the desired level of accuracy.
In classification problems, the Gradient Boosting algorithm uses a set of decision trees to predict the probability that a data point belongs to each possible category. The category with the highest probability is then assigned as the predicted category for the data point.
Similarly, in regression problems, the Gradient Boosting algorithm uses a set of decision trees to predict the numerical value of the output variable. The predicted value is a weighted average of the outputs predicted by each tree in the model.
Optimisation With Gradient Descent
Gradient Descent is a mathematical optimization technique that is commonly used in machine learning to minimize the error of a model by adjusting its parameters. The goal is to find the best possible set of parameters to make the model as accurate as possible.
In Gradient Descent, the model's error is measured by a loss function, which calculates the difference between the predicted values and the actual values of the data. The goal is to minimize the loss function, which will lead to a more accurate model.
To minimize the loss function, Gradient Descent starts with an initial set of parameters and then iteratively adjusts them in small steps to minimize the error. It does this by calculating the gradient of the loss function with respect to the parameters and then updating the parameters in the opposite direction of the gradient. This process is repeated until the error is minimised, or until a stopping criterion is met.
In Gradient Boosting, Gradient Descent is used to optimize the parameters of each decision tree in the ensemble. The goal is to find the best possible set of weights for each tree so that the ensemble can make the most accurate predictions.
XGBoost is an advanced machine learning algorithm that is a variant of gradient boosting. It's popular because it's fast, efficient and has good performance. It uses a technique called 'regularization' to prevent overfitting, which is when the model is too complex and fits the training data too well but performs poorly on new data.
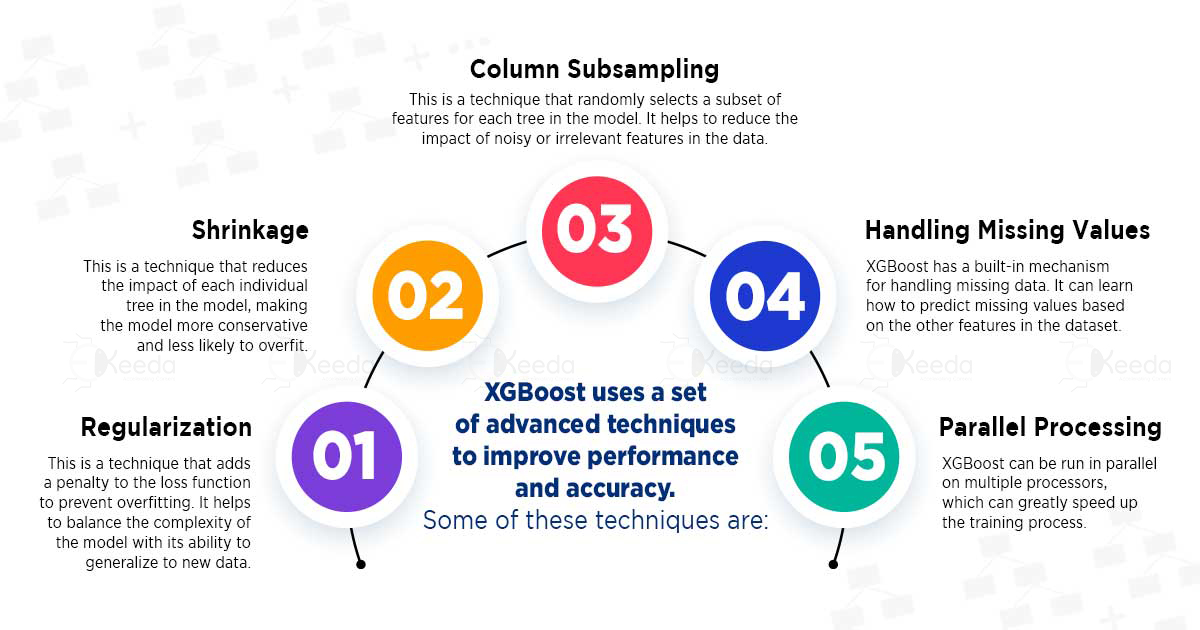
XGBoost uses a set of advanced techniques to improve performance and accuracy. Some of these techniques are:
Regularization: This is a technique that adds a penalty to the loss function to prevent overfitting. It helps to balance the complexity of the model with its ability to generalize to new data.
Shrinkage: This is a technique that reduces the impact of each individual tree in the model, making the model more conservative and less likely to overfit.
Column Subsampling: This is a technique that randomly selects a subset of features for each tree in the model. It helps to reduce the impact of noisy or irrelevant features in the data.
Handling Missing Values: XGBoost has a built-in mechanism for handling missing data. It can learn how to predict missing values based on the other features in the dataset.
Parallel Processing: XGBoost can be run in parallel on multiple processors, which can greatly speed up the training process.
Real-World Applications Of Gradient Boosting
Real-world applications of gradient boosting using Machine Learning techniques include fraud detection, customer churn prediction, image and speech recognition, and personalized recommendation systems, among others.
Online Advertising: Gradient Boosting is used by companies like Google, Facebook, and Yahoo to improve their online advertising. They use this technique to predict which ad will be most relevant to a particular user based on their search history, demographic information, and other factors.
Fraud Detection: Banks and financial institutions use Gradient Boosting to detect fraudulent transactions. This is done by training a model on historical data and then using it to identify anomalies in new transactions.
Image And Speech Recognition: Gradient Boosting is used in computer vision and speech recognition applications to identify patterns and features in images and speech. It can help to accurately classify images and transcribe speech into text.
Medical Diagnosis: Gradient Boosting is used in medical diagnosis to predict the likelihood of a patient having a certain condition. This is done by training a model on patient data and then using it to predict the likelihood of a certain condition based on symptoms and other factors.
Self-Driving Cars: Gradient Boosting is used in self-driving cars to accurately identify objects in the environment and make decisions based on that information. This is done by training a model on large datasets of images and sensor data and then using it to make predictions in real-time.
Healthcare: Gradient Boosting is used in the field of healthcare for predicting disease risk, identifying high-risk patients, and identifying optimal treatment plans. For example, Gradient Boosting can be used to predict the risk of a heart attack based on a patient's medical history.
Image And Video Recognition: Gradient Boosting is used for image and video recognition tasks such as object detection, facial recognition, and gesture recognition. For example, Gradient Boosting can be used to recognise faces in a crowd of people or to identify the presence of a specific object in an image.
Natural Language Processing: Gradient Boosting is used in natural language processing tasks such as sentiment analysis, language translation, and speech recognition. For example, Gradient Boosting can be used to determine the sentiment of a customer's review of a product or to translate text from one language to another.
Marketing: For consumer segmentation, lead scoring and product suggestions, marketers employ gradient boosting. For example, Gradient Boosting can be used to segment customers based on their buying behaviour and to recommend products to them based on their past purchases.
A Word From Ekeeda
Gradient Boosting is a powerful machine learning algorithm that has many real-world applications in fields such as finance, healthcare, and e-commerce. It has the ability to handle complex data and produce accurate predictions, making it an essential tool for data scientists.
At Ekeeda, we offer a comprehensive Data Science course that covers Gradient Boosting, as well as other important machine learning algorithms and techniques. Our course is intended to give you the information and abilities you need to be successful in this captivating field.
By enrolling in our course, you'll gain a competitive edge and open up new career opportunities. Start your journey towards becoming a data scientist today with Ekeeda.

Q: What Is Gradient Boosting, And Why Is It Used In Data Science?
Gradient Boosting is a machine learning technique that is used for both regression and classification problems. It can handle large datasets and is effective in solving complex problems with high accuracy.
Q: How Is Gradient Boosting Different From Other Machine Learning Techniques?
Gradient Boosting is different from other machine learning techniques because it combines multiple weak learners to create a strong learner. It trains one weak learner at a time, and each subsequent learner is trained to correct the errors made by the previous one.
Q: Is It Necessary To Have A Strong Mathematical Background To Learn Gradient Boosting?
A strong mathematical background is not necessary to learn Gradient Boosting. However, some mathematical concepts like calculus, linear algebra, and probability theory can help us understand the concepts better.
Q: Can Learning Gradient Boosting Lead To A Career In Data Science?
Yes, learning Gradient Boosting can lead to a career in Data Science. Many companies require machine learning experts to solve complex problems, and having skills in Gradient Boosting can give you an edge in the job market.
Q: Do I Need To Have Prior Programming Experience To Learn Gradient Boosting?
Yes, you need to have prior programming experience to learn Gradient Boosting. Knowledge of programming languages like Python or R is essential, and familiarity with data manipulation libraries like Pandas, Numpy, and Scikit-learn can be beneficial.

Join our army of 50K subscribers and stay updated on the ongoing trends in the design industry.

I hope you enjoyed reading this blog post
Book call to get information about Data Science & placement opportunities

Your test is submitted successfully. Our team will verify you test and update in email for result.































































































































































































































































































